Evaluate GenAI
New
All-in-One Creative for Retail Platform with Accurate, Scalable Evaluations.
Best GenAI Model
A Comparative Study Using Tasq.ai’s Eval Genie
LLM Comparison
Tailor-made model comparison for accurate insights
Ranking & Surveys
Customizable ranking for precise feedback
Computer Vision
AI-driven visual analysis for versatile applications
Data Validation
Ensuring data accuracy and reliability
Data Enrichment
Enhance datasets with additional context
Data Collection
Gather valuable data at scale
Content Moderation
Ensuring Safe and Respectful Content
Video Annotations
Detailed frame-by-frame analysis
Image Annotations
Precision labeling for diverse image sets
Transcription(OCR)
Fast, accurate text extraction
Similarity
Advanced similarity detection
Model Validation & Tuning
Optimize models for peak performance
Foundation Models
Ready-to-use models for diverse applications
Blog
Case Studies
AI Model Acceleration
Boosting AI model development.
Customer Insights Analysis
Insights through data analysis.
Sentiment Enhancement
customer sentiment, AI technology.
Image Labeling Use
Product labeling in eCommerce.
Retail Checkout Solution
Seamless checkout for retail chains.
Fast Image Labeling
Labeling images with advanced AI.
Pest Detection Field
Finding pests with AI in agriculture.
Generative AI Quality
Measuring AI using crowds.
Constructions & Safety
Drones & Robotics
E-Commerce & Retail
Agriculture
Autonomous Vehicles
Sport Media & Entertainment
Webinars & Video
Glossary
Generate. Evaluate. Launch! All-in-One Platform with Accurate, Scalable Evaluations.
Trusted by:
Effortless AI Generation and Evaluation in 4 Easy and Simple Steps
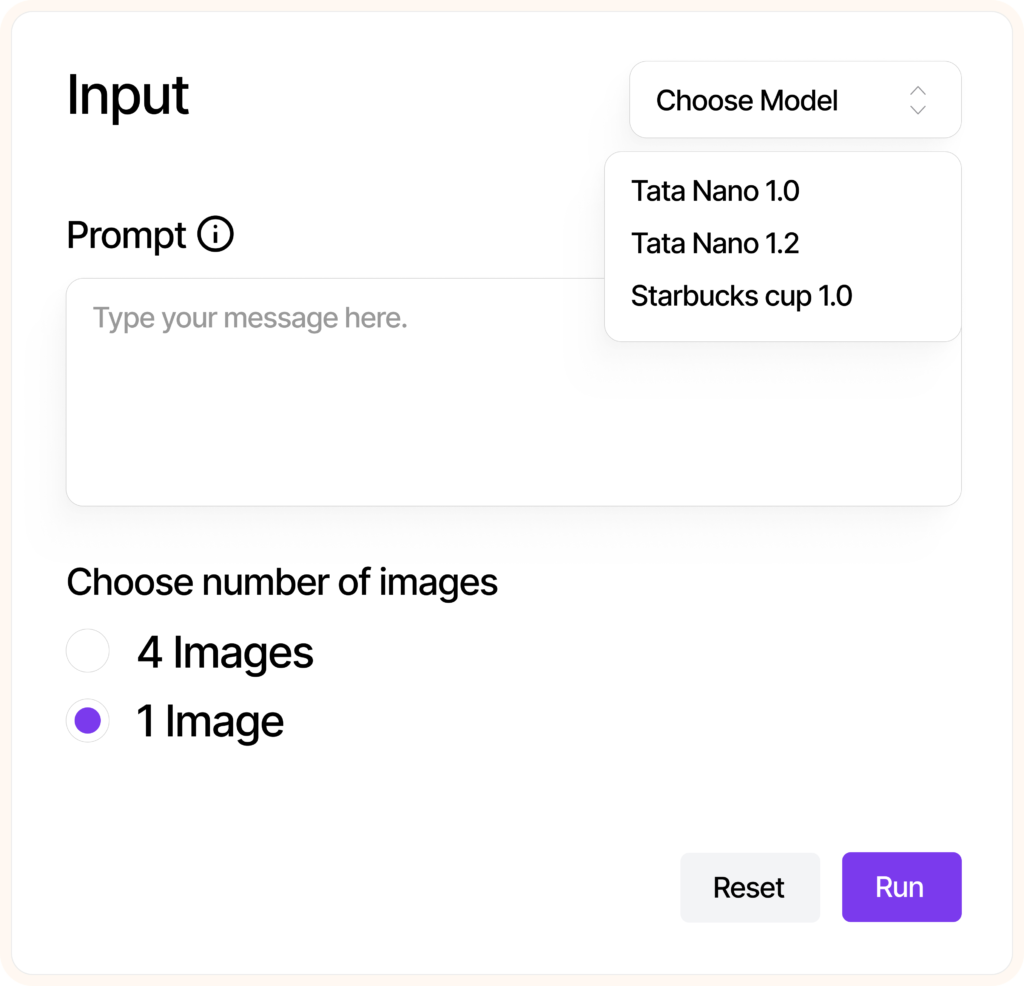
Plug model into EvalGenie with ease.
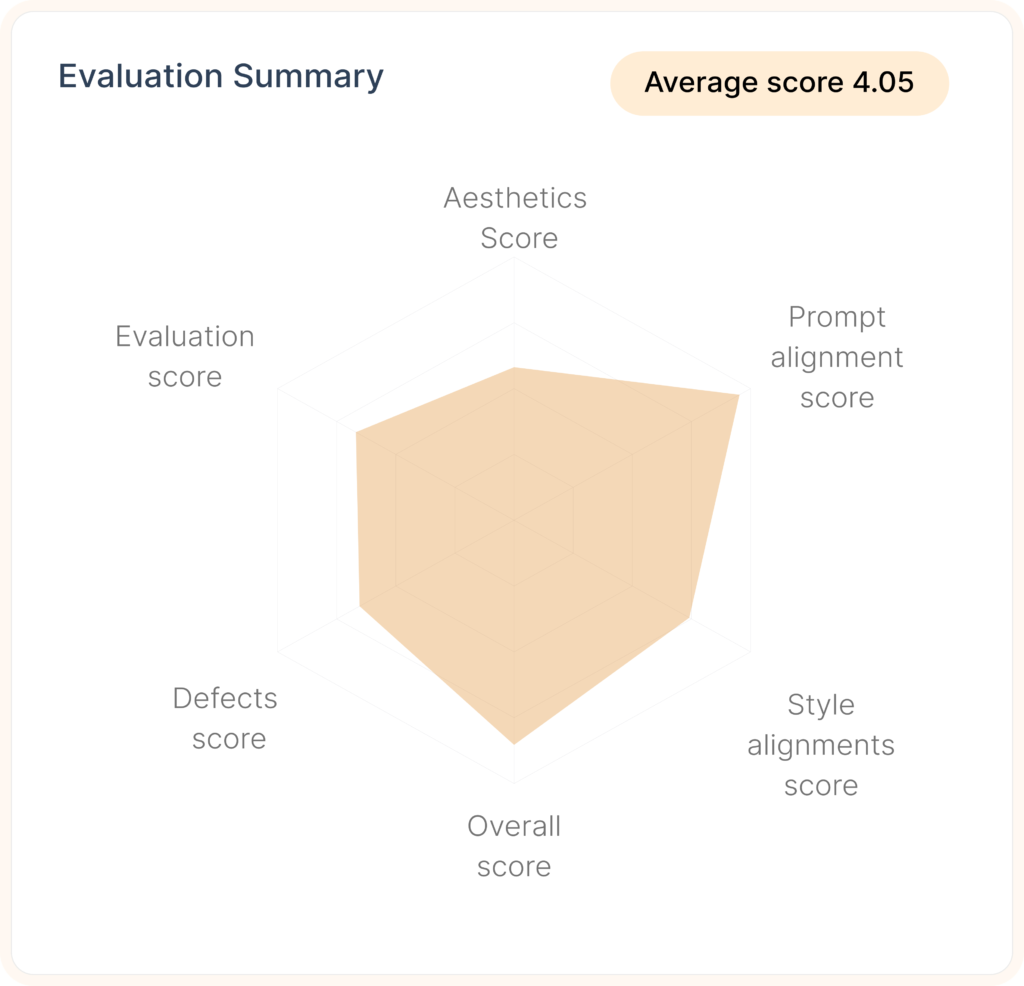
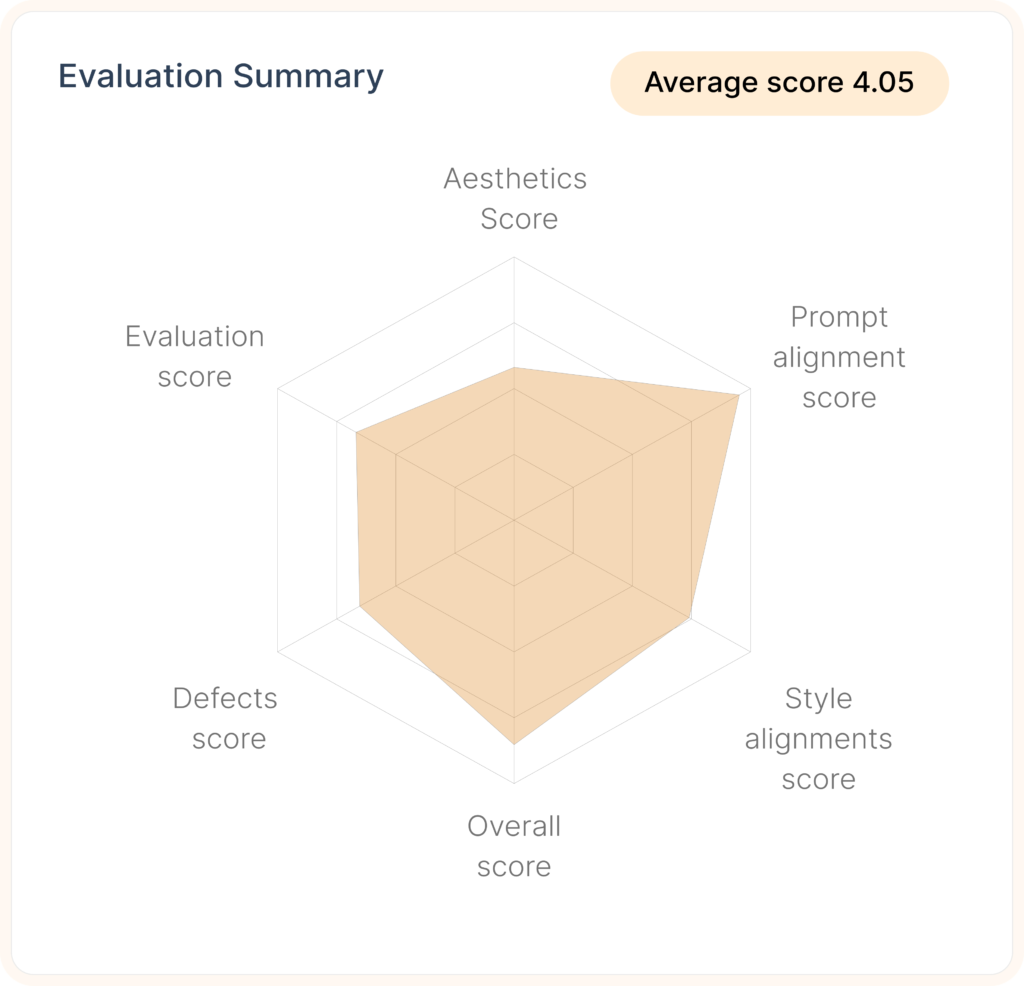
Validate the quality of assets on Geo-Targeted crowds
Generate assets (Ads, Catalog, PDP, images etc..) interactively.
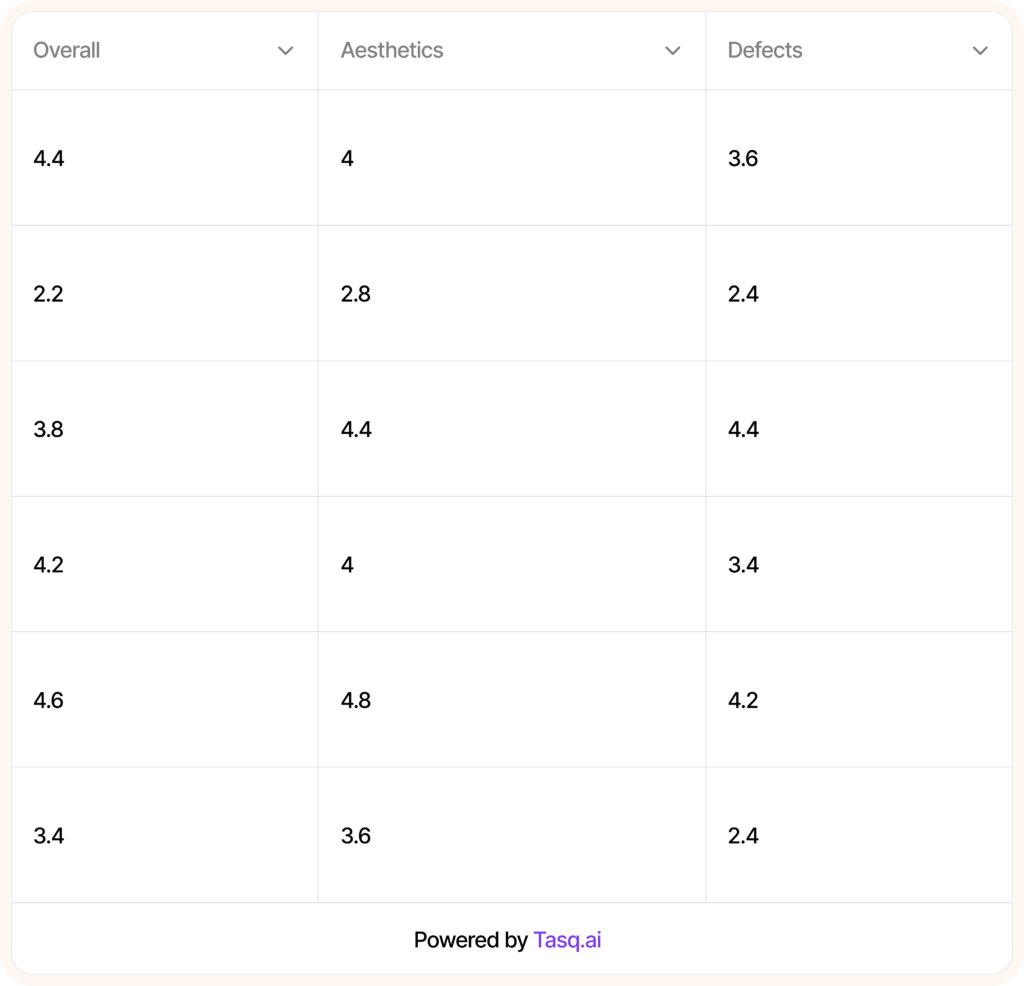
Access detailed insights via comprehensive dashboard.
Streamline Creative
Guess
Work