Tasq.ai’s Hybrid AI Workflows ensure 99% accuracy at any scale with unparalleled flexibility, radically refining your AI outputs to drive reliable decision making.
Tasq.ai’s unique global reach and hybrid pipelines allowed us to navigate language barriers effectively, ensuring accuracy even in challenging cases. Smooth onboarding, great service, no effort on our side.
Omer Kehat
VP Product, Revuze
Tasq.ai’s unique solution enabled us to collect dynamic judgments from a massive, diverse crowd in an extremely cost-effective way, faster than any other solution we evaluated.
Yair Adato, PhD
CEO, BRIA
We’ve been working with Tasq.ai for the past year, and continually impressed by the results they deliver. With Tasq.ai’s platform, we’ve been able to streamline our data labeling process and significantly improve the accuracy of our machine learning models.
Yuval Wartelsky
Data Strategy Manager
As a startup company, we required diverse services at a fast pace and varying volumes. Tasq team demonstrated exceptional flexibility and delivered results that exceeded our expectations. Their data labeling work was impressive, with remarkably high accuracy rates. Their web platform enabled us to operate with maximum efficiency. After working with several vendors in the field, Tasq proved to be the perfect solution for our needs.
Dana Friedman
Product Manager, FruitSpec
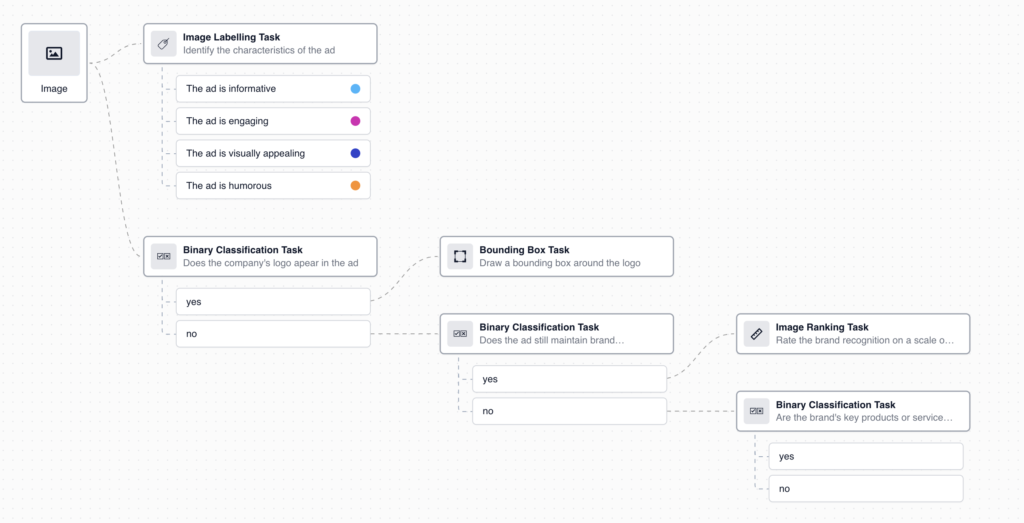
Tasq.ai Offers You
Customized Hybrid Workflows blending world-class models, global decentralized human guidance, and subject matter experts, all tailored to your data for maximum results.
Configurable AI Flow Platform
Tasq.ai offers a groundbreaking platform that enables organizations to seamlessly customize AI technologies to their needs, simplifying integration and driving innovation. You’re not just adopting AI—you’re shaping the future of your business.
Configure workflows based on your unique requirements, ensuring optimal results for specific AI tasks.
Easily scale up or down depending on project size, from small to enterprise-level applications.
Use automated workflows, reducing manual intervention and accelerating AI development.
Decentralized Human Guidance
By combining the best of human insights into the fabric of machine intelligence, our innovative platform brings you Decentralized Human Guidance: enabling unmatchable accuracy, scaling, seamlessness, and flexibility. It’s AI, but with a human touch—ethical, adaptable, and aligned with your most complex needs. Step into the future with Tasq.ai.
Leverage human insight to fine-tune AI models for better precision and reliability.
Utilize a global workforce of experts from different domains to enrich your AI models.
Ensure ethical AI development through human supervision.
Best-in-Class Models
At Tasq.ai, we empower our clients with access to the best models available, enabling unparalleled accuracy and efficiency, and ensuring these are made applicable to your use case. You can implement these in your AI workflows, add Decentralized Human Guidance, and constantly optimize results to create a sustainable long-term decisive business advantage.
Leverage world-class models that deliver consistently high-quality results across various applications, ensuring robust performance.
Benefit from models that evolve with decentralized human input, maintaining efficiency as new data and scenarios emerge.
Our models are built to adapt and evolve, helping your business stay ahead of the curve in an ever-changing landscape.
What We Do
Tasq.ai orchestrates the ML and GenAI lifecycle by combing world-class models and seamless human guidance for leading AI practitioners.
Curate & label datasets
With unique Decentralized Human Guidance for seamless automation & allocation of globally distributed Tasqers
Fine-tune your model
Best-in-class models optimized on your data, enabling you to plug into, embrace and benefit from the ecosystem
Solve accuracy issues
Combine the best of humans and machines in an endless process of optimization providing accuracy
Continuously improve
Your models train automatically as labeled data accumulates, ensuring models autonomously adapt and evolve, with highest ethical standards
Constantly monitor
Enjoy peace of mind knowing your models are constantly evaluated – even generative AI is kept in check thanks to Decentralized Human Guidance
Tasq Solver
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
How You Benefit
Our innovative AI solutions combine human-guided insights and world-class models to deliver unparalleled accuracy and flexibility.
With seamless integration and responsible AI practices at the core, our platform is built to optimize your AI processes and empower your business for long-term growth
Accurate
True accuracy is driven by unyielding comparison to ground truth, constant comparisons of human answers, checking, validating, and relentless optimization across the entire lifecycle until you get to the ultimate decision.
Seamless
Experience the smoothest data-related process imaginable with our white-glove service, ensuring absolute peace of mind. Join the ranks of our enterprise clients who are exponentially growing their AI capabilities with us.
Scalable
Our unique architecture facilitates explosive scaling with just a few clicks. Whether you’re working on niche projects or massive LLMs, your experience will remain consistently smooth.
Flexible
With our solution, your data and models are tailored to your specifications, offering unmatched versatility. Focus on creating intelligent applications while easily training, optimizing, evaluating, fine-tuning and improving your models.
Responsible AI
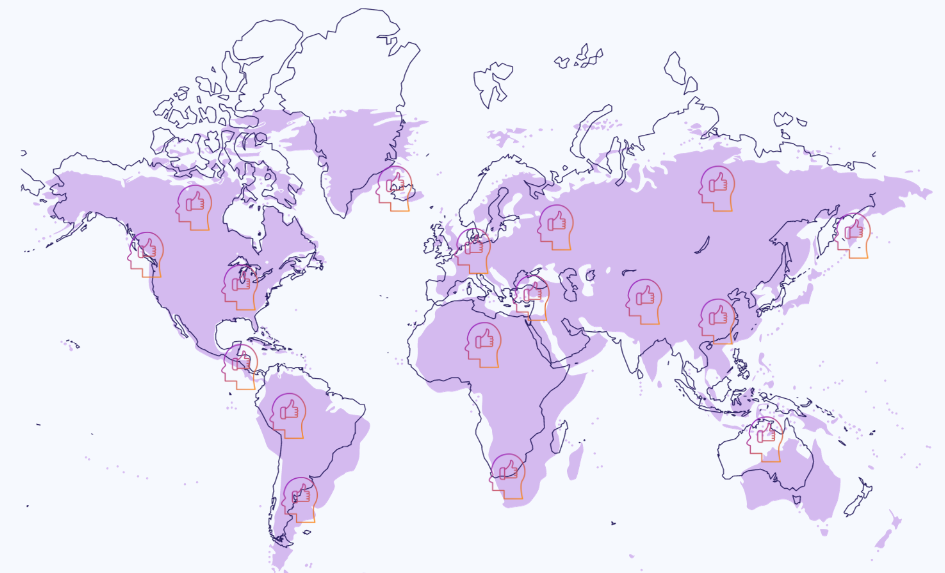
We prioritize the delivery of more responsible AI by embedding Decentralized Human Guidance into our process. Our global reach includes every country in the world, removing bias and ensuring consistent results.
Tasq Must-Reads
Discover the latest AI insights and innovations, from groundbreaking models to industry trends, and see how Tasq.ai is transforming the AI landscape
Tasq.ai works with leading GenAI companies, enterprises, and government agencies.
Praise From Our Clients
Omer Kehat
VP Product, Revuze
Tasq.ai’s unique global reach and …
hybrid pipelines allowed us to navigate language barriers effectively, ensuring accuracy even in challenging cases. Smooth onboarding, great service, no effort on our side.
See more
Yair Adato, PhD
CEO, BRIA
Tasq.ai’s unique solution enabled us to collect dynamic judgments from…
a massive, diverse crowd in an extremely cost-effective way, faster than any other solution we evaluated. ..
We’ve been working with Tasq.ai for the past year, and continually impressed by the results they deliver…
With Tasq.ai’s platform, we’ve been able to streamline our data labeling process and significantly improve the accuracy of our machine learning models. The support team at Tasq.ai has been incredibly responsive and helpful, making the entire experience seamless and enjoyable. I highly recommend Tasq.ai to any business looking to harness the power of AI for real-world impact.
See more
Praise From Our Clients
Omer Kehat
Tasq.ai’s unique global reach and…
hybrid pipelines allowed us to navigate language barriers effectively, ensuring accuracy even in challenging cases. Smooth onboarding, great service, no effort on our side.
Tasq.ai’s unique solution…
enabled us to collect dynamic judgments from a massive, diverse crowd in an extremely cost-effective way, faster than any other solution we evaluated.
We’ve been working with Tasq.ai for…
the past year, and continually impressed by the results they deliver.
With Tasq.ai’s platform, we’ve been able to streamline our data
labeling process and significantly improve the accuracy of our
machine learning models. The support team at Tasq.ai has been incredibly responsive and helpful,
making the entire experience seamless and enjoyable. I highly recommend Tasq.ai to any business
looking to harness the power of AI for real-world impact.
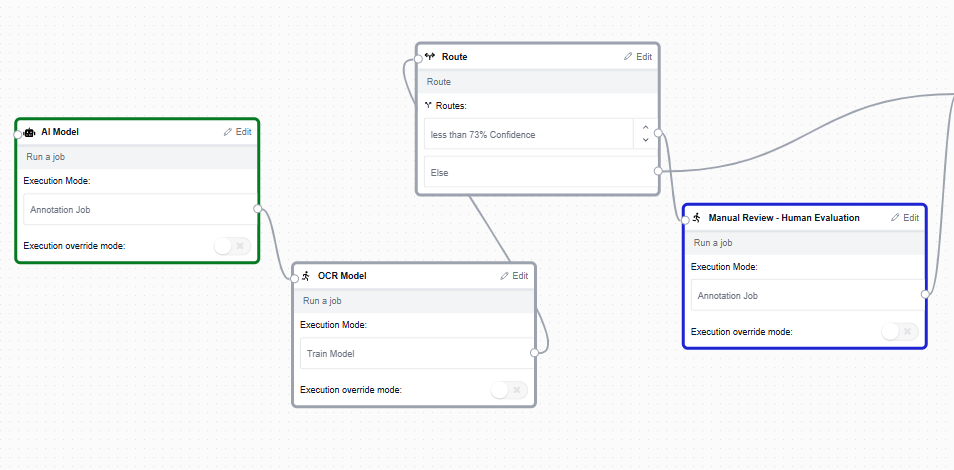
A customized AI flow, tailored to your data, using Decentralized Human Guidance and world-class models to optimize your results.
Configurable AI Flow Platform
Tasq.ai introduces a transformative approach to artificial intelligence with its configurable AI flow platform. This innovative solution empowers organizations to effortlessly adapt AI technologies to their specific needs, streamlining operations and enabling innovation. It’s the gateway to unlocking the full potential of AI, making complex integrations a thing of the past. With Tasq.ai, you’re not just adopting AI; you’re customizing the future of your business.
Decentralized Human Guidance
By combining the best of human insights into the fabric of machine intelligence, our innovative platform brings you Decentralized Human Guidance: enabling unmatchable accuracy, scaling, seamlessness, and flexibility. It’s AI, but with a human touch—ethical, adaptable, and aligned with your most complex needs. Step into the future with Tasq.ai.
Best-in-Class Models
At Tasq.ai, we empower our clients with access to the best models available, enabling unparalleled accuracy and efficiency, and ensuring these are made applicable to your use case. You can implement these in your AI workflows, add Decentralized Human Guidance, and constantly optimize results to create a sustainable long-term decisive business advantage.
What We Do
Tasq.ai orchestrates the ML and GenAI lifecycle by combing world-class models and seamless human guidance for leading AI practitioners.
The Complete DataOps System
Curate & label datasets
With unique Decentralized Human Guidance for seamless automation & allocation of globally distributed Tasqers
Fine-tune your model
Use best-in-class models optimized on your data, enabling you to plug into, embrace and benefit from the ecosystem
Solve your accuracy issues
Combine the best of humans and machines in an endless process of optimization providing unprecedented accuracy
Continuously improve
Your models train automatically as labeled data accumulates, ensuring models autonomously adapt and evolve, with highest ethical standards
Constantly
monitor
Enjoy peace of mind knowing your models are constantly evaluated – even generative AI is kept in check thanks to Decentralized Human Guidance
Tasq Solver - Continously Improving
How You Benefit
Accurate
True accuracy is driven by unyielding comparison to ground truth, constant comparisons of human answers, checking, validating, and relentless optimization across the entire lifecycle until you get to the ultimate decision.
Seamless
Experience the smoothest data-related process imaginable with our white-glove service, ensuring absolute peace of mind. Join the ranks of our enterprise clients who are exponentially growing their AI capabilities with us.
Scalable
Our unique architecture facilitates explosive scaling with just a few clicks. Whether you're working on niche projects or massive LLMs, your experience will remain consistently smooth.
Flexible
With our solution, your data and models are tailored to your specifications, offering unmatched versatility. Focus on creating intelligent applications while easily training, optimizing, evaluating, fine-tuning and improving your models.
Responsible AI
We prioritize the delivery of more responsible AI by embedding Decentralized Human Guidance into our process. Our global reach includes every country in the world, removing bias and ensuring consistent results.