In a recent webinar, we showed how Tasq.ai’s LLM evaluation analysis led to a 71% improvement in results.
In the dynamic world of AI, where every algorithmic breakthrough propels us into the future, Tasq.ai, in collaboration with Iguazio (now part of McKinsey), has set a new precedent in the realm of Machine Learning Operations (MLOps). Our recent participation in the enlightening webinar, “How can you validate, evaluate and fine-tune an LLM effectively?” has provided us with a treasure trove of insights and methodologies that are redefining the industry standards.
Hosted by McKinsey, the webinar brought together luminaries from the AI world, including our very own Dr. Ehud Barnea, Head of AI at Tasq.ai, who joined Yaron Haviv and Guy Lecker from Iguazio. The collective expertise offered a panoramic view of applying MLOps in real-world scenarios, scrutinizing the challenges and unearthing solutions that many had only theorized about until now.
Crafting the Foundations of AI: A Vision by Yaron Haviv
The webinar commenced with a profound narrative by Yaron Haviv, who dissected the AI application construction into four critical components: data construction, model development, model evaluation, and deployment into production. This comprehensive breakdown not only emphasized the challenges in evaluating LLMs for accuracy but also showcased the importance of a nuanced, multi-faceted approach to AI application development.
Shaping the Future of Chat Models with Dr. Ehud Barnea
Dr. Ehud Barnea, our Head of AI, elevated the conversation by sharing his expertise in developing chat models, addressing the often-overlooked complexities that surface during production. With his guidance, we delved into the practical steps required to overcome these hurdles, highlighting Tasq.ai’s unique approach to refining the ‘evaluation’ phase, which is crucial in the development of robust and efficient AI systems.
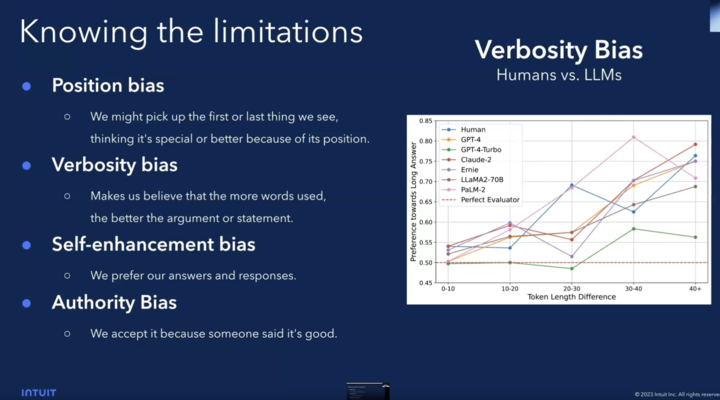
Debunking AI Myths: A Realistic Approach to Open Source Models
When looking deeply into open-source models, the webinar provided a reality check against the inflated expectations from new models that claim to surpass the likes of ChatGPT. Here, Tasq.ai’s philosophy shone through, stressing the importance of realistic benchmarks that mirror real-world AI applications. This strategy ensures that each LLM is evaluated for its practical efficacy, not just theoretical performance.
The Use Case
The use case was a retail one- McStyle, a fashion company that would like to create a fashion chatbot on their website.
Just like any other chatbot the expectation are-
▪ Recommend website items based on the customer’s preferences.
▪ Offer #fashion tips according to the website styling.
▪ Answer questions about the website policies – shipping, returns, etc.
▪ Be polite and follow the company’s code of conduct
The goal was to improve it with Tasq.ai human feedback.
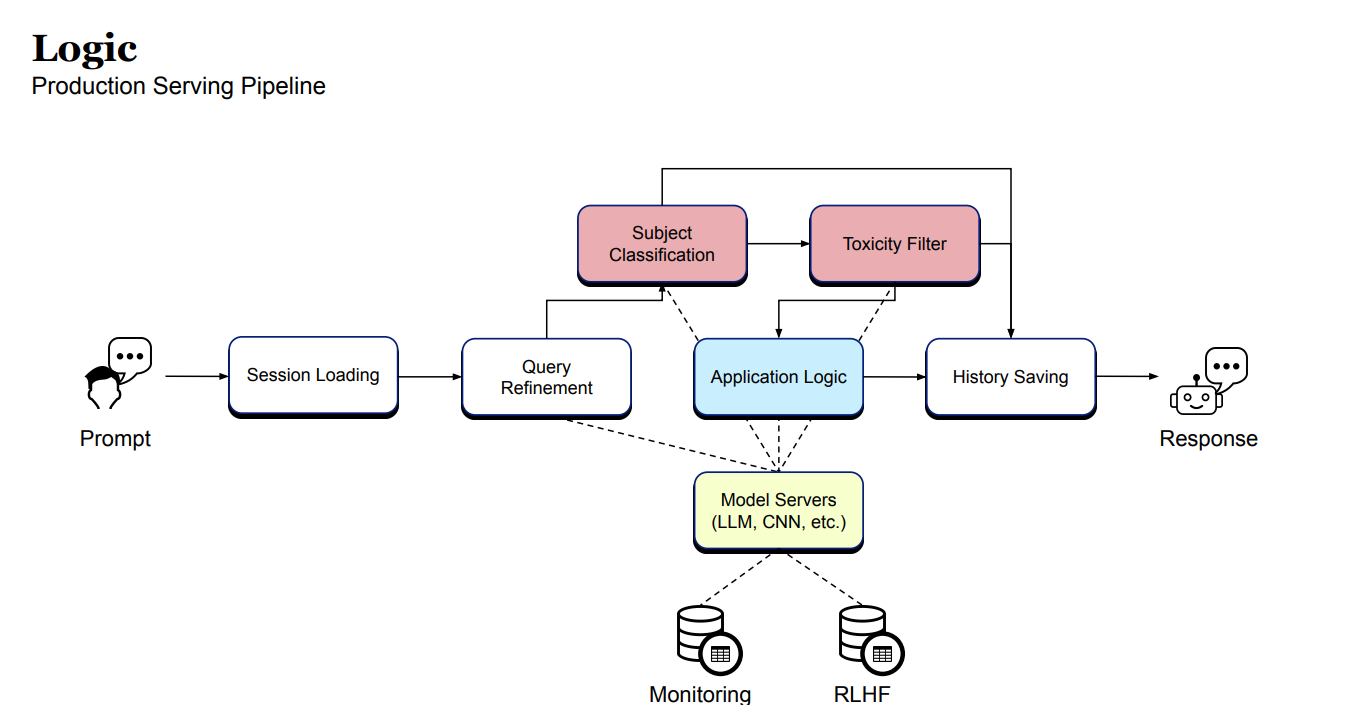
Therefore the logic and architecture we build for the experiment was the following:
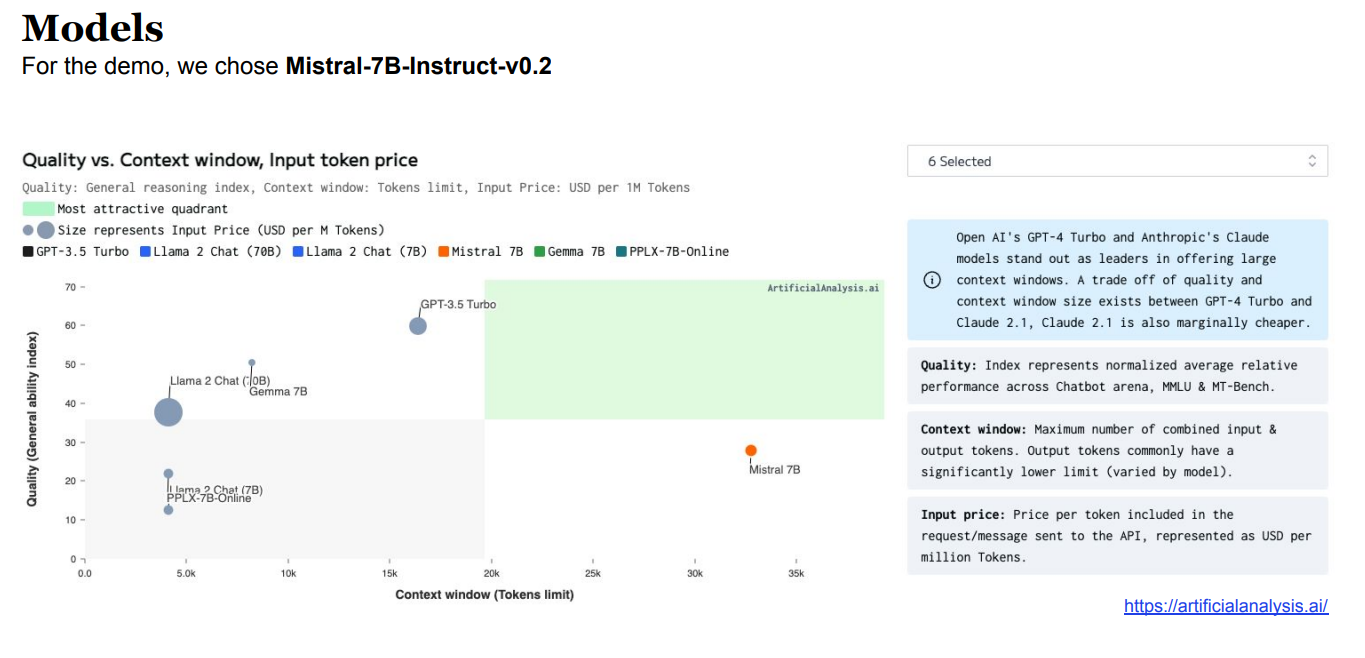
For the demo, Mistral-7B-Instruct-v0.2 was chosen , the reason for it was the combination of quality and context.
Using the MLRun’s model server the team collected the input prompt and the output prompts for various nodes within the application graph.
Several steps were done to improve the model –
1. The team removed the fashion tips and inferred Mistral again with its “default taste” in fashion so the model will adjust itself to the crowd’s taste
2. ~30 samples of input prompts and our expected output the model should reply. Then the team inferred them to Mistral to sample its inputs.
3. The team engineered guidelines and code of conduct into the input prompts and inferred the model again to get better replies to the original inputs.
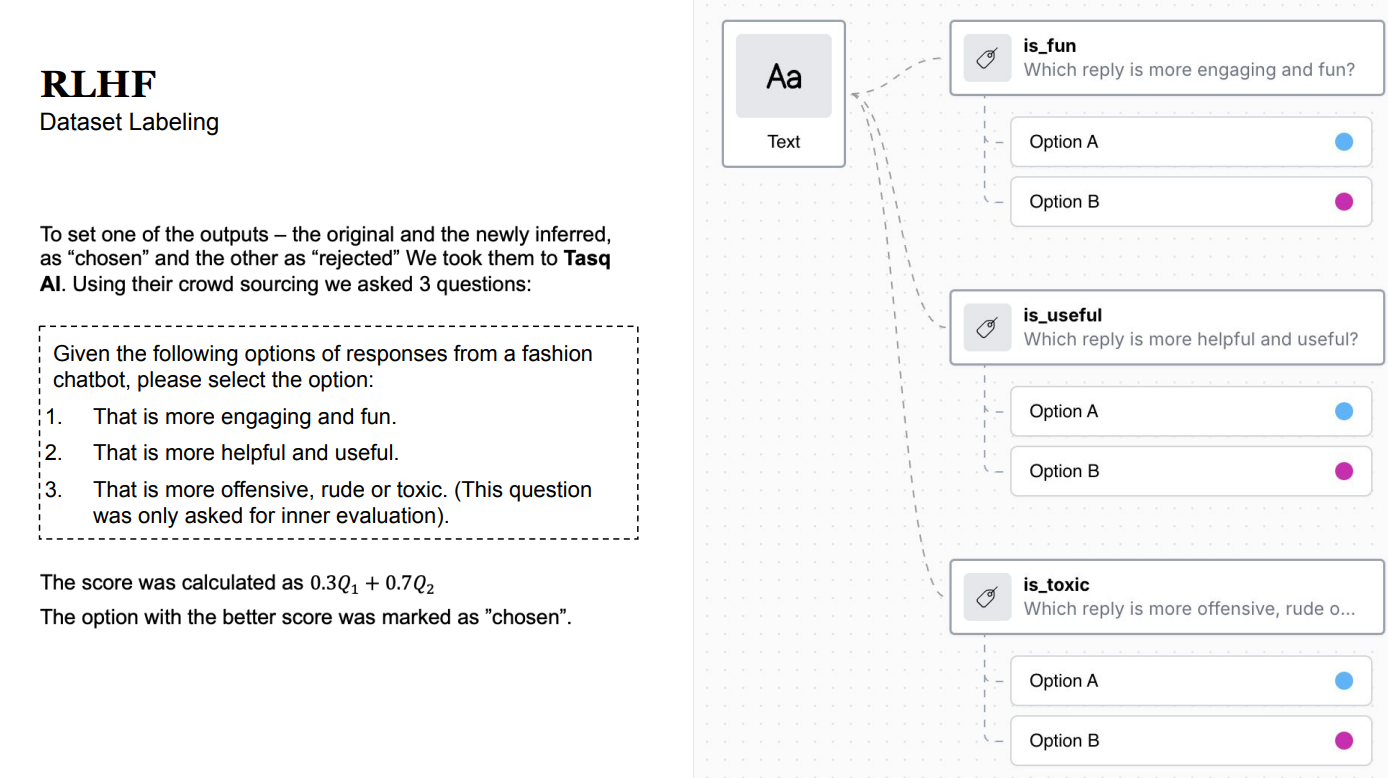
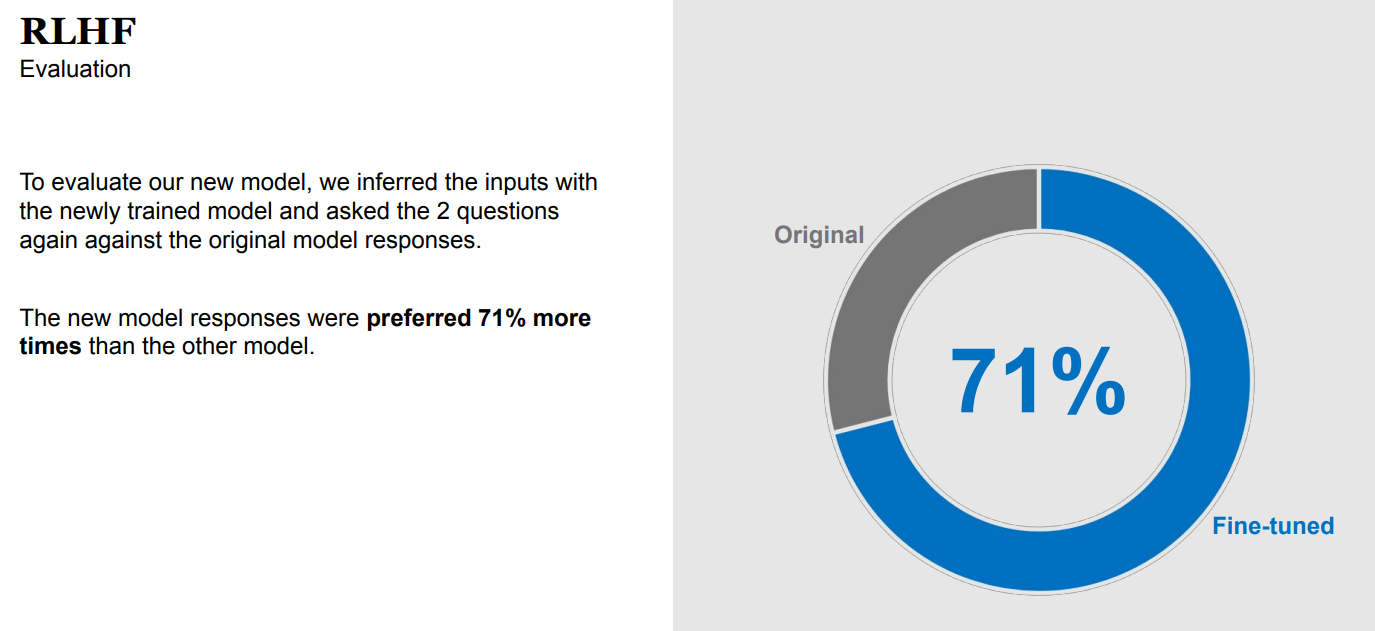
The Process– To evaluate our new model, the team inferred the inputs with the newly trained model and asked the Tasq.ai crowd 2 questions again against the original model responses.
At Tasq.ai, we’ve crafted a transformative platform that seamlessly integrates world-class models with essential human guidance.
The human guidance shown below is easy to configure, modify and scale across a global diverse crowd.
The results: Real-World SuccessThe new model responses were preferred 71% more times than the other model.
Our work with McStyle epitomizes our mission—transforming the AI experience from a one-size-fits-all to a tailored journey. By choosing Mistral-7B-Instruct-v0.2 model and enriching it with Reinforcement Learning from Human Feedback (RLHF), we’ve improved the chatbot. The evolution from a standard Q&A bot to an engaging, intuitive, and brand-aligned advisor led to a remarkable 71% user preference rate, setting a new standard for AI chatbots in retail.
Tasq.ai: Customizing the Future
Our experience at the webinar reinforced what we at Tasq.ai have always known: the true potential of AI lies in its ability to learn, adapt, and grow in real-world environments. Whether through the global crowd validation process or the meticulous tuning of models to align with specific tasks, Tasq.ai is not just adopting AI—we’re redefining it.
We invite you to join us on this exhilarating journey as we continue to push the boundaries of what AI can achieve. Let’s collaborate to tailor the future of your business with AI that’s not just powerful but also personal.